

你所关注的都在这里
小菜鸟的个人博客于2021年5月20日正式上线且对外开放啦...
与此同时,本人近期萌生了一个比较强烈的计划,那就是打算持续性输出大数据技术生态(但不限于)相关的系列文章。
可想而知这是一项“宏伟工程”,想要一直坚持下去应该还是比较难的,毕竟想法很丰满,现实却又是如此的骨感。工作 + 生活,不一定什么时候就有什么事给那啥了…
但是吧,小菜鸟既然放话出来了,那就不是随便说说的,更何况再怎么说我也是个地地道道且纯血统的技术人员,怎么能拖了大佬们的后腿呢,坚决不能够的,所以这里不只是想想而已,“肯定是”说干就干(虽然我加了引号,但就不承认是引号里面的人),对的,你没看错,我就是这么倔强。
好啦,话不多说,言归正传。可能部分人会有些疑问说:既然这些技术点工作中大多都有用到过,那应该总体掌握还是比较熟练的,本来平时工作就比较忙了,为什么还要花费较多的时间在发表总结性文章上面,学点新的技术框架它不香么?周末不上班出去逛逛它不美么?找个三五好友出去喝个小酒它不爽么?…
呃… 这样感觉确实很不错。但是吧,不管是出去逛还是喝小酒,又或者是其它的周末娱乐活动,需 ...

线上 HIVE 作业因死锁导致作业卡死问题排查 - 原因分析与解决方案
线上 HIVE 作业因死锁导致作业卡死问题排查 - 原因分析与解决方案
前言因为关系型数据库 RDBMS 死锁造成的线上问题的排查和解决,大家一般都比较熟悉;但大数据中的死锁问题,大家一般都没有遇到甚至没有听说过。 最近笔者在某客户线上生产环境就频繁多次遇到了该问题,某些HIVE SQL 作业(底层非HIVE ACID事务表),因为迟迟获取不到HIVE锁导致作业长时间卡死,最后运维人员不得不登录hs2后台手动通过命令查找并释放死锁,才最终解决问题。
问题现象某些HIVE SQL作业,正常十几分钟即可执行完毕,但有时运行三十多分钟后仍没有成功,怀疑作业卡死;为排查问题,在后台通过beeline登录hs2并直接提交sql进行尝试,发现作业同样存在阻塞。阻塞超过一定时间后,任务直接报错:
123456789101112131415161718192021222324252627282930313233343536373839404142ERROR : FAILED: Error in acquiring locks: Locks on the underlying objects canno ...

使用 Git Hook 自动部署 Hexo 到个人 VPS
配置服务器远程 Git大家都知道 Git 是分布式的版本控制系统,远程仓库跟本地仓库是没有什么不同的。
我的 VPS 系统是 Ubuntu 14.04 的,在 Ubuntu 上配置 Git 是相当简单的。
第一步安装 git:
1sudo apt-get install git
第二步创建一个 git 用户,用来运行 git 服务:
1sudo adduser git
虽说现在的仓库只有我们自己在使用,新建一个 git 用户显得不是很有必要,但是为了安全起见,还是建议使用单独的 git 用户来专门运行 git 服务
第三步创建证书登录,把自己电脑的公钥,也就是 ~/.ssh/id_rsa.pub 文件里的内容添加到服务器的 /home/git/.ssh/authorized_keys 文件中,添加公钥之后可以防止每次 push 都输入密码。
如果你之前没有生成过公钥,则可能就没有 id_rsa.pub 文件,可参考如下步骤:
123456789101112# 生成密钥对ssh-keygen -t rsa# 生成之后 ~/.ssh 目录下就会有对应的公钥和密钥# 如果 /home ...

Springboot配置websocket,https使用 WebSocket 连接
提示:本文简单介绍websocket与http的区别及如何在项目中使用websocket,以springboot项目为例
一、http协议与websocket协议区别
WebSocket
一种在单个连接上进行全双工通信的协议。WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
用于Web应用中需要实现动态刷新的场景,大量数据定时刷新,数据轮询等操作场景,例如在线聊天、网页游戏、实时数据分析等。支持双向通信,实时性更强,更好的二进制支持,更小的控制开销:协议包头较小。同时支持扩展。
HTTP
HTTP一种单向的请求-响应协议,即客户端向服务器发送请求,服务器响应后连接关闭。这种模式限制了服务器主动向客户端推送信息的能力。用户想刷新一次数据就需要请求一次后台。
HTTP更适合于传输静态内容或简单的请求-响应场景,如网页浏览。
二、使用步骤
1.引入库
1234<dependency> ...

CDH5.12.0-HiveServer2-java.net.SocketTimeoutException(Read timed out)
一. 问题背景
基于CDH构建离线数仓,在通过JDBC向HiveServer2提交作业时出现java.net.SocketTimeoutException: Read timed out 错误,导致大批量的作业失败,不能按时产生数据,已严重影响到业务运行。
二. 集群环境
CDH-5.12.0Hive-1.1.0
三. 错误日志
提交作业客户端报的错误日志如下:
12345678910111213141516171819202122232425262728293031323334353637383940414243java.sql.SQLException: org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:263) at org.apache.hive.jdbc.HiveStatement.execu ...
理解`(ds|hr)?+.+`
在hive/spark sql可以支持对列名进行正则匹配,其中给出这样一个 例子:
A SELECT statement can take regex-based column specification in Hive releases prior to 0.13.0, or in 0.13.0 and later releases if the configuration property hive.support.quoted.identifiers is set to none.
1SELECT `(ds|hr)?+.+` FROM sales
这个查询会查找除了ds和hr之外的所有列。这个正则实在是太过少见,查阅了很多资料才理解了。
首先要正确拆分(ds|hr)?+.+,(ds|hr)?+是一段,后面.+是第二段。这里面难点在于(ds|hr)?+的意义,子匹配(也就是括号)后面跟了两个量词?+,这是特殊用法,按照一般的量词意义是无法理解的,这个用法就是占有优先量词。正则的量词包括忽略优先、匹配优先、占有优先,占有优先是最大匹配后不“交还”,这点和匹配优先相反。这个例子的 ...

Hive中collect_list()排序问题详解
来看一道互联网公司的面试题:
123有个用户好友表:字段如下uid fans_uid score返回:uid, fans_uid_list【fans_uid的拼接串,按照score降序拼接】
给出数据源:每个uid,有很多对应的fans_uid,每个fans_uid 都对应一个score,我们需要按uid分组,将fans_uid 的score按降序排序,将fans_uid 放在一个列表中,做好友推荐
123456789101112131415161718192021222324252627create temporary table tb_user_fans as select 1 as uid,'a' as fans_uid,3 as scoreunion allselect 1 as uid,'b' as fans_uid,1 as scoreunion allselect 1 as uid,'c' as fans_uid,4 as scoreunion allselect 1 as uid,'d& ...

Voice of April
以下内容来源于网络:原文链接 默认静音播放,可手动调节打开音量
上海疫情爆发一个月,网上看到过的太多发声,没过多久就消失了一大半,时间长了已经有些麻木,但有些事情不应该发生,既然发生了也不应该被遗忘。太多同胞受了本可以避免的苦,全国这么多支援的情况下怎么还会变成这样呢?
2022年四月的上海能在家不挨饿的已经属于幸运。作为电影人,在亲身经历后如果什么也不做真的有些负罪感。因为时长原因最后选取了四月上旬二十多个事件的部分音频,正好也有无人机能纪录下周边现在的样子,做了一个视频当做一种尽量客观真实的纪录,来记住4月的这些声音,希望所有人都能挺过去。
愿山河无恙,愿人间皆安!
让我们一起守沪!上海!加油!

Hive 优化之SQL优化
小表 Join 大表 将 key 相对分散,并且数据量小的表放在 join 的左边,可以使用 map join 让小的维度表先进内存。在 map 端完成 join。 实际测试发现:新版的 hive 已经对 “小表 JOIN 大表” 和 “大表 JOIN 小表” 进行了优化。小表放在左边和右边已经没有区别。
MapJoin 工作机制
参数设置1234-- 设置自动选择 Mapjoinset hive.auto.convert.join=true; -- 默认为 true-- 大表小表的阈值设置(默认 25M 以下认为是小表)set hive.mapjoin.smalltable.filesize=25000000;
样例 SQL 1. 小表 JOIN 大表语句
1234select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_urlfrom smalltable sjoin bigtable bon b.id = s.id;
2. 大表 JOIN 小表语句
1234select b.id, b.t, b ...
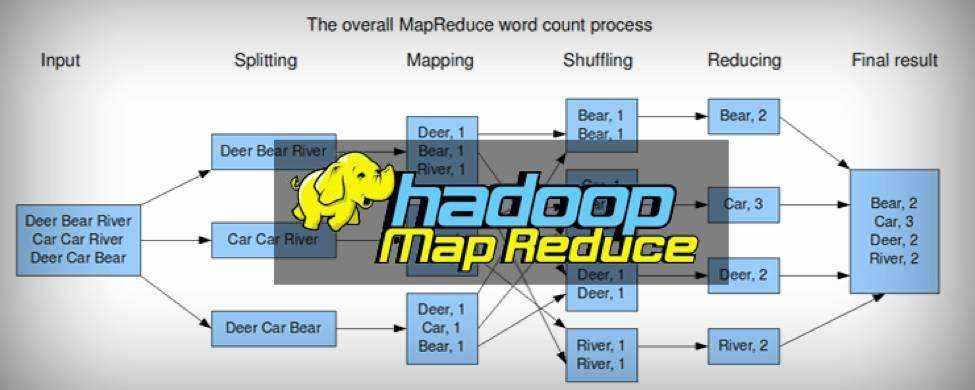
Hive 优化总结整理版
慎用api 我们知道大数据场景下不害怕数据量大,害怕的是数据倾斜,怎样避免数据倾斜,找到可能产生数据倾斜的函数尤为关键,数据量较大的情况下,慎用 count(distinct),count(distinct) 容易产生倾斜问题。
设置合理的map reduce的task数量map阶段优化1234mapred.min.split.size: -- 指的是数据的最小分割单元大小;min的默认值是1Bmapred.max.split.size: -- 指的是数据的最大分割单元大小;max的默认值是256MB通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
举例: a. 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128M的块和1个12M的块),从而产生7个map书; b. 假设input目录下有3个文件a,b,c,大小分别为10M,20M,130M,那么hadoop会分隔成4个块(10M,20M,128M,2M ...

{kind=link}