
线上 HIVE 作业因死锁导致作业卡死问题排查 - 原因分析与解决方案
线上 HIVE 作业因死锁导致作业卡死问题排查 - 原因分析与解决方案
前言
因为关系型数据库 RDBMS 死锁造成的线上问题的排查和解决,大家一般都比较熟悉;但大数据中的死锁问题,大家一般都没有遇到甚至没有听说过。 最近笔者在某客户线上生产环境就频繁多次遇到了该问题,某些HIVE SQL 作业(底层非HIVE ACID事务表),因为迟迟获取不到HIVE锁导致作业长时间卡死,最后运维人员不得不登录hs2后台手动通过命令查找并释放死锁,才最终解决问题。
问题现象
某些HIVE SQL作业,正常十几分钟即可执行完毕,但有时运行三十多分钟后仍没有成功,怀疑作业卡死;为排查问题,在后台通过beeline登录hs2并直接提交sql进行尝试,发现作业同样存在阻塞。阻塞超过一定时间后,任务直接报错:
1 | ERROR : FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time |
引发问题的原因:
FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
Hive中有两种锁模式,分别为:共享锁(S) 和 排它锁(X)。
多个共享锁(S)可以同时获取,排它锁(X)会阻塞其它所有锁。
如果select一张表,这张表则会进入shared模式,增加、插入、删除、修改数据和修改表名等操作都会在shared锁被释放之后再执行,会一直等待。
如果插入、删除、修改数据则进入Exclusive锁模式,进入排他锁模式之后不允许增删改操作,会报错
ERROR : FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time org.apache.hadoop.hive.ql.lockmgr.LockException: Locks on the underlying objects cannot be acquired. retry after some time
简单推荐的处理方式:
- 释放掉Exclusive锁模式即可操作。
- 在代码里面添加:set hive.support.concurrency=false;
问题排查思路与问题原因
通过 ==show locks== 命令查看集群中目前已有的所有hive 锁,并基于问题SQL的具体内容推断是否需要特定HIVE锁,从而推断是否可能存在死锁;
注意排查类似死锁问题时,我们可以通过命令 ==show locks extended==,==show locks table_name extended== 或 ==show locks table_name partition (partition_spec)== 查看锁的详细情况,该命令除了会显示锁对应的 table_name 和 lock_mode, 还会显示 lock_queryid, lock_time, lock_querystring 等更多细节,从而更容易定位到锁对应的SQL内容和提交时间,如下图所示:
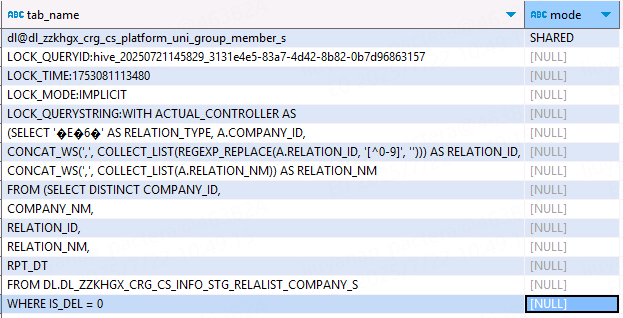
在这里我们定位到集群中某些SQL持有了某张表的 shared 共享锁且迟迟没有释放(事实上该SQL对应的jdbc session早就断开退出了),导致我们的SQL获取不到该表的exclusive排他锁,从而导致我们的SQL作业卡死,即因为死锁导致了作业卡死;
通过翻阅hs2的后台日志,也清晰提示出现了锁竞争:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
422024-01-05 21:17:20,706 ERROR ZooKeeperHiveLockManager: [HiveServer2-Background-Pool: Thread-499670]: Other unexpected exception:
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method) ~[?:1.8.0_221]
at org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager.lock(ZooKeeperHiveLockManager.java:304) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager.lock(ZooKeeperHiveLockManager.java:208) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager.acquireLocks(DummyTxnManager.java:181) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.Driver.acquireLocksAndOpenTxn(Driver.java:1237) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1607) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1332) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1327) [hive-exec-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.1.1]
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) [hive-service-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.2.1]
at org.apache.hive.service.cli.operation.SQLOperation.access$600(SQLOperation.java:92) [hive-service-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.2.1]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:345) [hive-service-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.2.1]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_221]
at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_221]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) [hadoop-common-3.0.0-cdh6.2.1.jar:?]
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:357) [hive-service-2.1.1-cdh6.2.1.jar:2.1.1-cdh6.2.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_221]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_221]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_221]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_221]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_221]
2024-01-05 21:25:20,736 ERROR ZooKeeperHiveLockManager: [HiveServer2-Background-Pool: Thread-499670]: Unable to acquire IMPLICIT, EXCLUSIVE lock xx after 100 attempts.
2024-01-05 21:25:20,738 ERROR org.apache.hadoop.hive.ql.Driver: [HiveServer2-Background-Pool: Thread-499670]: FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
org.apache.hadoop.hive.ql.lockmgr.LockException: Locks on the underlying objects cannot be acquired. retry after some time
at org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager.acquireLocks(DummyTxnManager.java:184)
at org.apache.hadoop.hive.ql.Driver.acquireLocksAndOpenTxn(Driver.java:1237)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1607)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1332)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1327)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256)
at org.apache.hive.service.cli.operation.SQLOperation.access$600(SQLOperation.java:92)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:345)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:357)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
问题解决
解决方式1:手动查看并释放死锁
由于这里使用了 hive 默认的锁机制,即只适用于非事务表的锁机制,
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager;
set hive.lock.manager=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager;
这种锁机制下支持手工通过unlock命令解除hive锁,所以直接通过命令 ==unlock table dl.dl_zzkhgx_crg_cs_platform_uni_group_member_s== 解除过期的hive表锁,此后重新提交SQL作业即可。
解决方式2:客户端配置参数 set hive.support.concurrency=false 以不使用HIVE的并发锁机制
我们也可以在客户端 session 级别配置参数 set hive.support.concurrency=false,此时执行HIVE SQL时,不会使用 HIVE 的并发锁机制,即不会检查目前系统中已有的锁也不会尝试加锁和解锁,自然也就不会阻塞。
注意此时需要由调度系统确保不会并发更新同一张表或同一个表分区,同时写数据时如果有并发读,可能会脏读。
需要说明的是,在合理配置调度系统的情况下,该方案的风险性其实并不大,因为从技术角度讲,spark 各个版本都是不支持锁的, TDH平台的 inceptor 也是不支持锁的
解决方式3:客户端配置参数 ==set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager== 以使用另一套HIVE锁机制
我们也可以在客户端 session 级别配置参数 set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager,以使用另一套HIVE锁机制,由于两套HIVE锁机制的内部实现不同,彼此是完全隔离的(两套锁机制互相看不到对方的锁),自然也就不会阻塞。
事实上,hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager 是HIVE 新版本(2.x及以上)的并发锁机制,适用于所有表,包括事务表和非事务表,底层固定搭配使用的是 hive.lock.manager= org.apache.hadoop.hive.ql.lockmgr.DbLockManager;
而 hive.txn.manager= org.apache.hadoop.hive.ql.lockmgr.DummyTxnManagerHIVE 是新版本(2.x及以上)模拟的老版本的并发锁机制,且只适用于HIVE 非acid事务表,其底层固定搭配使用的是hive.lock.manager= org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager ;
如果使用只适用于非事务表的锁机制 DummyTxnManagerHIVE,读写acic事务表,会报错:
1
Error while compiling statement: FAILED: SemanticException [Error 10265]: This command is not allowed on an ACID table xxx with a non-ACID transaction manager. Failed command: xxx (state=42000,code=10265))
解决方式4:配置使用更大的 hive thrift socket time out
我们也可以配置使用更大的 hive thrift socket time out,以减小 thrift socket time out 发生的可能,从而避免出现未释放的HIVE过期锁(当然另一方面,可以想办法提升集群性能,以减小 thrift socket time out 发生的可能)。
由于该方案涉及到代码改动,且新老版本配置hive thrift socket time out的具体方式不同,本文暂不展开该方案。
什么情况下HIVE自身的锁机制可能会残留过期锁
问题虽然解决了,但如果进一步追问,HIVE自身的锁机制,为什么没能自动清理残留的过期HIVE锁,却不太好回答。目前遇到过的/能想到的情况,主要有:
- hs2 服务进程所在的服务器异常重启,导致 hs2 进程异常退出;
- hs2 服务进程因OOM或其它原因(比如Kill -9暴力杀死),导致异常退出(未能优雅退出并重启);
- 在没有使用ACID事务表时,默认使用的hive锁实现是hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager;hive.lock.manager=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager;此时依赖一个健康的ZK集群,所以如果ZK异常重启或发生了比较严重的GC等问题,也可能会出现问题;
- 客户端创建到hs2的jdbc连接后即可成功获取session,在此session下提交SQL后,会首先解析编译该SQL,然后会获取相关的hive锁,最后才会执行底层的任务(可能是分布式的MR/SPARK/TEZ任务,也可能是HS2的本地任务),其中解析编译SQL使用一套线程池(HiveServer2-Handler-Pool: Thread-XXXXX),加锁执行任务和解锁使用另一套线程池(HiveServer2-Background-Pool: Thread-XXXXX),在任务执行过程中,如果客户端和hs2的session因为某些原因断开了,hs2就会通过jvm线程之间的interrupt 机制取消任务的执行并释放hive锁,但在interrupt机制下,部分hive锁有可能因为被interrupt不能成功释放,从而导致残留部分过期锁,后续其它session提交的需要获取这些锁的sql作业就会因获取不到锁导致失败。
- 最后一种情况最为复杂,在该客户现场,残留的过期HIVE锁未能自动释放的原因,正是这种情况;
此时,其相关的hs2日志如下:
1 | # 客户端成功创建到 hs2 的jdbc链接,获得 session |
此时,相关的客户端日志如下:
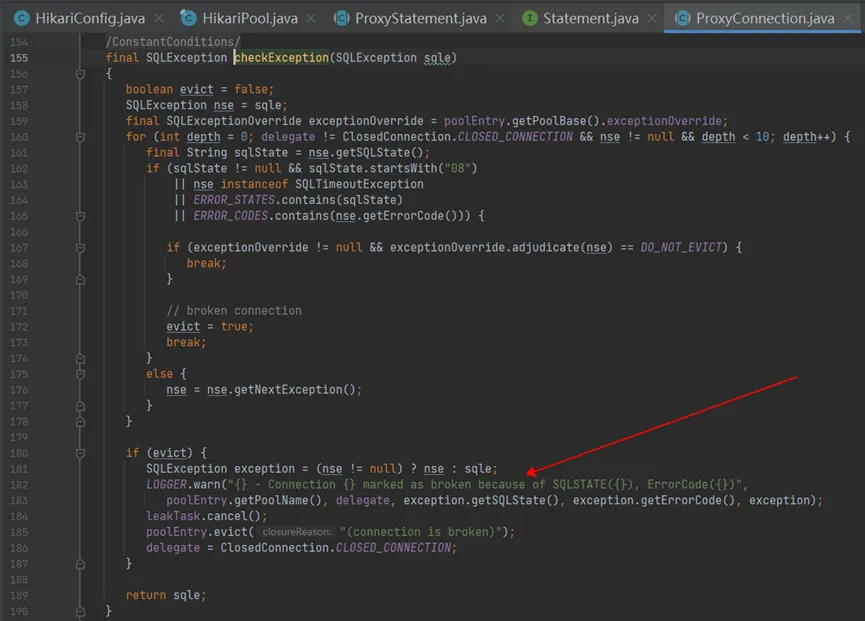
1 | 2024-01-04 19:41:53.878 [1454594]|[WARN] [executeExportTaskScheduler-1] [com.zaxxer.hikari.pool.ProxyConnection:157] -HikariPool-1 - Connection org.apache.hive.jdbc.HiveConnection@4a8e04e8 marked as broken because of SQLSTATE(08S01), ErrorCode(0) |
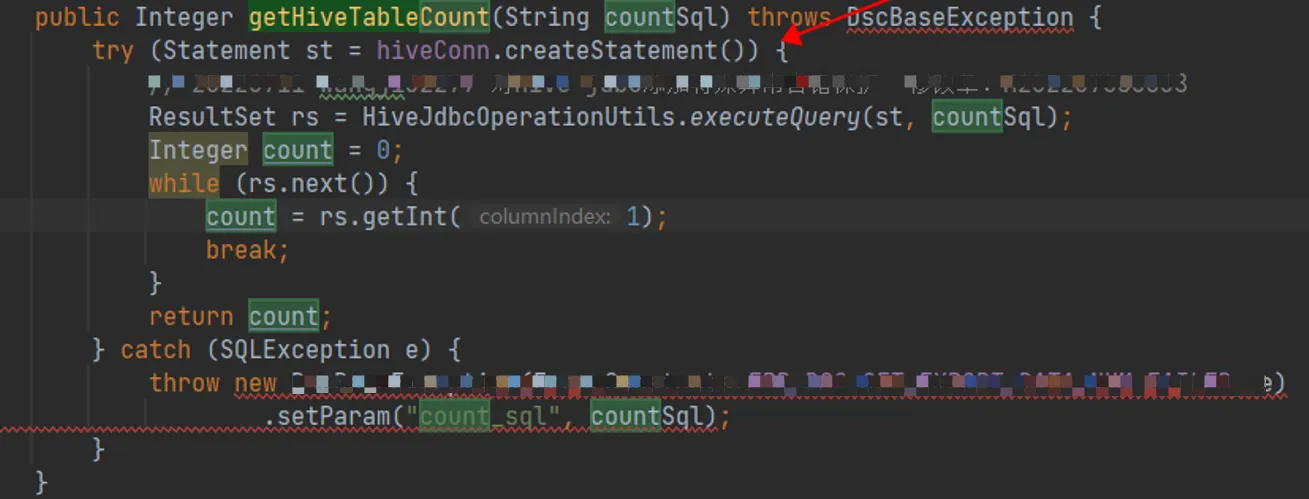
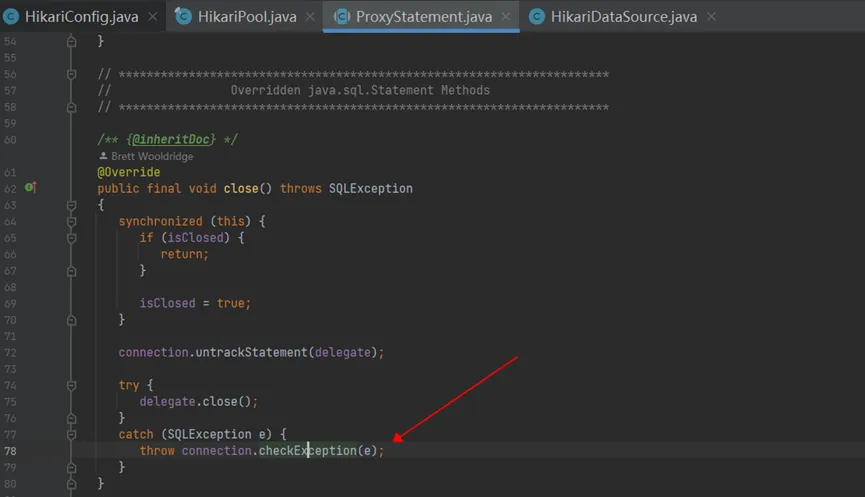
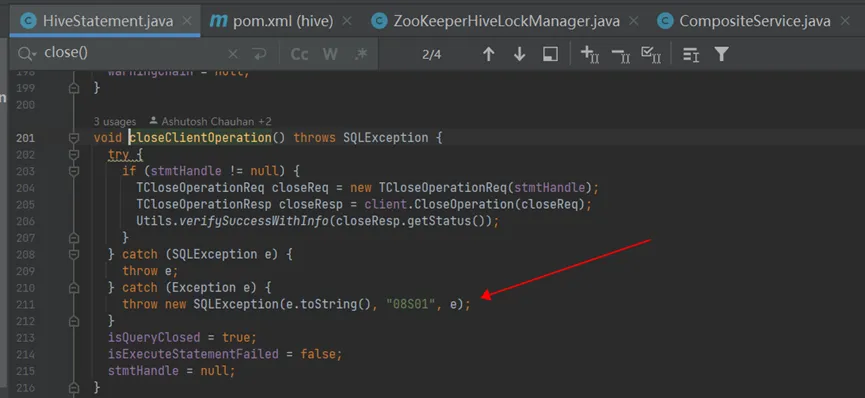
- 注意应用程序,Hikari和hive jdbc对应的源码如下,可以看到,应用程序通过 java 的try-with-resources,确保了SQL执行异常时会关闭statement 的代理对象delegate;而Hikari在关闭statement的代理对象delegate时,会关闭其底层真实的HiveStatement,在HiveStatement关闭异常时,会校验并关闭其对应的异常的 Connection 对象,并打印日志”{} - Connection {} marked as broken because of SQLSTATE({}), ErrorCode({})”:
HIVE死锁问题总结
一般而言,HIVE死锁问题的问题现象,直接原因和解决方式都比较简单:
- 问题现象:死锁问题的一般表现是,SQL作业长时间阻塞卡死,执行不动(底层其实在不断尝试获取锁);
- 直接原因:死锁问题的直接原因比较清晰,一般是使用了只适用于非事表的锁机制(hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager,hive.lock.manager=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager),且在特定异常情况下,hive自身的锁机制因为某些原因没有成功清除残留的过期锁,此时通过命令show locks extended 结合仔细查阅hs2日志可以定位到原因;
- 解决方式:死锁问题的解决方法也比较明确,有多种方法,一是手动通过unlock table xx 解除残留的过期锁,二是客户端配置客户端配置参数set hive.support.concurrency=false以不使用HIVE的并发锁机制,三是客户端配置参数set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager 以使用另一套HIVE锁机制,四是配置使用更大的hive thrift socket time out。
- 该问题一般只出现在HIVE集群并发较大网络负载较高的情况下;
HIVE锁相关技术背景
- 由于历史原因,HIVE2.x及以上有两套锁机制(都是基于悲观锁机制)即只适用于非事物表的锁机制(hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager,hive.lock.manager=org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager),和同时适用于事务表和非事务表的锁机制(即hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager,hive.lock.manager= org.apache.hadoop.hive.ql.lockmgr.DbLockManager);
- 只适用于非事物表的HIVE锁机制(DummyTxnManager),支持手工通过lock/unlock命令加锁和解锁,在极端异常情况下,可能会出现残留的过期锁,此时需要通过命令 unlock table hs_ods.ods_cic_custtoacct 解除过期的hive表锁;
- 适用于非事物表和事务表的HIVE锁机制(DbTxnManager),不支持手工通过lock/unlock命令加锁和解锁(会报错:Current transaction manager does not support explicit lock requests),其背后有异步的过期锁检测和清理机制(基于类AcidHouseKeeperService),一般不会出现残留的过期锁;
- 只适用于非事物表的HIVE锁机制(DummyTxnManager),固定搭配ZooKeeperHiveLockManager,底层依赖一个健康的zk集群;
- 适用于非事物表和事务表的HIVE锁机制(DbTxnManager),固定搭配DbLockManager,底层不依赖zk集群;
- 两套HIVE锁机制的内部实现不同,彼此是完全隔离的(两套锁机制互相看不到对方的锁,通过命令show locks看不到彼此的锁),都可以在客户端 session 级别进行配置;
- 对事务表的所有操作(包括select查询),都需要使用 DbTxnManager 而不能使用 DummyTxnManager,否则会报错:This command is not allowed on an ACID table xx with a non-ACID transaction manager;
- DummyTxnManager 下, 我们也可以在客户端 session 级别配置参数 set hive.support.concurrency=false,此时执行HIVE SQL时,不会使用 HIVE 的并发锁机制,即不会检查目前系统中已有的锁也不会尝试加锁和解锁,自然也就不会阻塞;
- 使用 DbTxnManager 时,必须 set hive.support.concurrency=true (该参数默认值就是true),底层有并发锁机制,且底层固定使用的是DbLockManager, 底层有心跳机制,因为执行失败或被异常终止(比如ctrl+c)的 SQL查询,其底层隐士自动获得的锁,会在停止心跳后被自动释放,但因服务器异常宕机或其他异常情况,引起hs2进程的心跳机制不工作时,有可能会有过期的锁,此时需要手动清理残留的过期锁,但由于DbTxnManager不支持手动释放锁,所以需要到源数据库 metastore 中,手动删除表HIVE_LOCKS中过期锁对应的记录;
- 在大数据生态中,spark 各个版本都是不支持锁的, TDH平台的 inceptor 也是不支持锁的;一些湖仓一体框架如hudi/iceberg/deltalake,其底层使用的是基于mvcc的乐观锁机制,而不是类似hive的悲观锁机制。
 微信
微信 支付宝
支付宝










{kind=link}