
Hive万亿级表联合分析故障排查与优化过程
关键字:
Hive,万亿级,大表,join,联合查询
摘要:
随着大数据技术日趋成熟,行业生态愈发完善,腾讯云大数据团队服务的大客户越来越多。在笔者服务的众多大客户之中,PB级海量数据已经成为常态。笔者负责大数据技术支持的某个腾讯云大数据项目,单张数据表的行数超过万亿级、数据量PB级,而且还需要对万亿级数据表做表与表的多维分析。比如本文介绍的故障排查过程,客户提交的就是 “万亿级大表 join 普通表” 的海量数据关联多维分析任务。这类任务,如果不对大数据平台进行优化,往往很容易运行失败,而且排查过程异常艰难。
一、故障现象
客户的离线海量数据分析任务,底层使用Hive数仓进行存储,并使用hive sql进行分析。因为某些项目原因,hive sql的执行引擎,没有选择spark和tez,最终使用的是mr。客户在半个月前反馈一个故障信息:他们有一类sql任务,无论提交多少次,都会100%失败;其它类型的sql任务,均能运行成功。根据客户反馈的这个信息,可以基本判断,腾讯云大数据平台TBDS内部集成的Hive集群功能绝对是正常的,只是这一类sql任务需要进行 “某方面的故障排查和优化”。
二、故障分析
2.1 sql语句分析
既然是这一类任务均失败,则我们只需要从这一类任务入手分析即可。我们通过项目现场的驻场工程师拿到了sql语句,如下所示:
1 | create table dbname.tablename row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compression'='snappy') |
稍微分析上面的sql语句,可以知道这个任务主要对两张表做join,然后把join的结果存储到一张新表,类似于:
1 | create table t1 as select xxx from ( t2 join t3) |
按照一般的情况,这类任务也不复杂,属于非常普通的sql任务,为什么会100%失败呢?
我们通过客户那里了解到,sql语句设计到的两张Hive表:simba.dc_cdr是一张大表,大概有1.2万亿行、40列;simba.t_res_20190226145527属于普通表,数据量很小,只有几万行数据。因此,这类任务属于 “万亿级大表 join 普通表” 的海量数据关联多维分析任务。
得到这个信息之后,我们大概知道排查的方向,任务失败多半是因为mapreduce运行过程中,因为某些原因使得部分container出现了OutOfMomery(OOM),这在大表做join的过程中属于常见的故障。至于产生OOM的原因,一般都是两类:数据倾斜导致shuffle过程中部分container数据量过大,超过container内存;另一个原因就是配置的mapper和reducer内存太小。顺着这个思路,我们进行排查。
2.1.1 提高mapper和reducer的参数
我们让现场的同事自己做测试,通过把mapper和reducer的参数从4GB提高到16GB,然后做测试。5个sql任务,全部失败;mapper和reducer的参数再次提高到32GB,依然全部失败。内存参数不足导致的OOM,这个可能的原因被排除了。当然为了保险起见,我们还是建议客户至少设置mapper和reducer的参数不能低于8GB,防止其他sql可能出现内存不足导致的OOM。
2.1.2 排查数据倾斜情况
我们通过排查simba.dc_cdr这张万亿级大表存储在HDFS内部的所有分区的数据量,发现:
(1)这张表每个分区的数据量非常均匀,并不存在数据切斜的情况;
(2)几个关键字段取值,在1.2万亿行中,也不存在明显的取值分布不均衡的情况。 因此,数据倾斜这个因素也被排除了。
2.2 任务日志分析
我们通过分析AM和部分container的日志,确实发现了部分container存在OOM情况。但是,这部分失败的任务都迁移到其它container执行,而且成功。因此,OOM不是这类 “万亿级大表 join 普通表” 的海量数据关联多维分析失败的根本原因。
我们通过现场工程师将日志传递回公司,经过日志分析,发现了这类任务都有一个重要的特征:任务在yarn上面运行的最终状态不是FAILED,全部都是KILLED。这类任务最终是被“KILLED”进而导致失败的。非常诡异的现象呀!
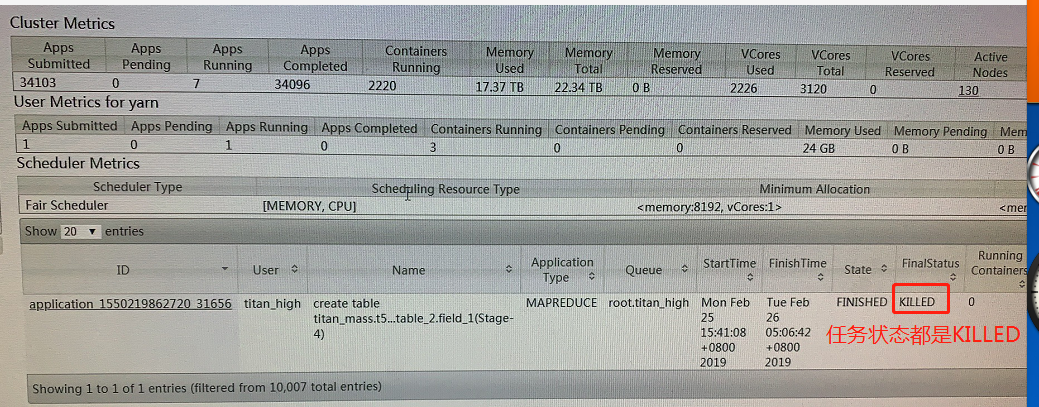
我们通过分析几个任务的AM日志,也得到以下信息:


1 | 2019-03-05 01:07:11,046 INFO [IPC Server handler 0 on 3860] org.apache.hadoop.mapreduce.v2.app.client.MRClientService: |
2.3 应用程序排查
既然任务都是被KILLED导致的失败,那么最大的可能就是被应用程序KILLED杀掉了。我们通过与应用程序开发者详细讨论,他们的确使用yarn application -kill命令去杀掉任务的情况,但是仅限于以下两种情况:
(1)任务运行的任务模型本身有误,被甲方客户在应用系统界面点击了“停止运行按钮”,然后应用系统下发了yarn application -kill appid命令杀死任务;
(2)任务运行过程中出现问题,比如无法获取任务的进度、无法获取任务的状态等,此时应用程序会下发yarn application -kill appid命令杀死任务。
我们在现场的同事自己做sql测试,不会触发上述两种情况,因此,这一类任务被“KILLED”,显然不是被应用程序、也不是被人为下发kill命令的。
三、最终确定故障原因
3.1 找出下发kill任务关键信息
既然不是应用程序下发的killed命令,也不是人为下发的kill命令,那么只可能是系统自己下发的kill命令。我们通过排查yarn、hive、mr的源代码,发现主动下发kill application命令的地方很多,如果逐一赛选可能会耗时太久。因此,最方便的方法,还是通过分析日志得到。
首先我们通过查看任务的AM日志、yarn resourcemanager的日志。对照日志分析,应该不是由yarn kill的:
(1)任务是client发起kill的,打日志的地方都在mr的client代码里面;
(2)yarn本身也无法获取到具体用户的认证信息,所以无法以某个用户的身份kill任务,如果kill的话只能以yarn用户身份。因此,确定yarn不会主动发起kill命令;
因此,最可能发起主动kill任务命令的就是hive或者mr。为了得到mr和hive客户端的日志信息,防止hiveserver2的干扰,我们跳过hiveserver2,直接采用原生hive shell进行sql测试,并且读取hive shell客户端的日志。通过日志,我们终于发现问题所在的关键点:
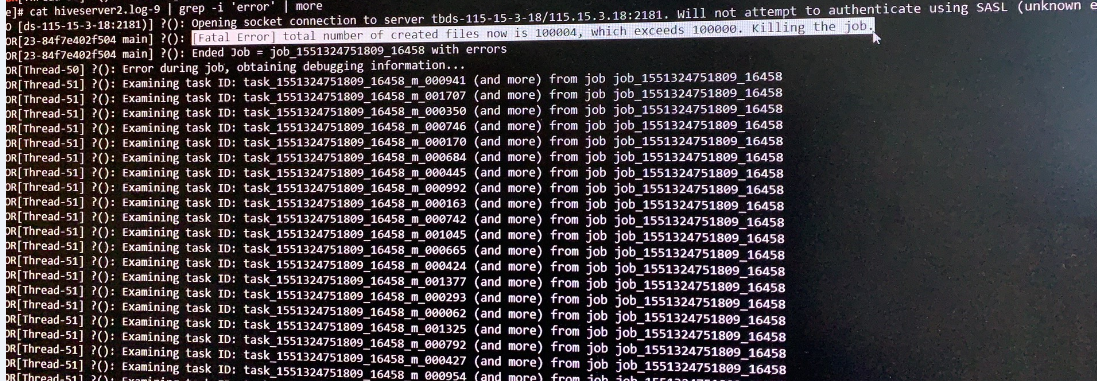
1 | [Fatal Error] total number of created files now is100004, which exceeds100000. Killing the job. |
也就是说,hive sql创建的文件数量运行到此时已经达到100004,超过100000个,因此下发了kill 任务的命令。
我们查看hive的源码,确实也发现了这一段:
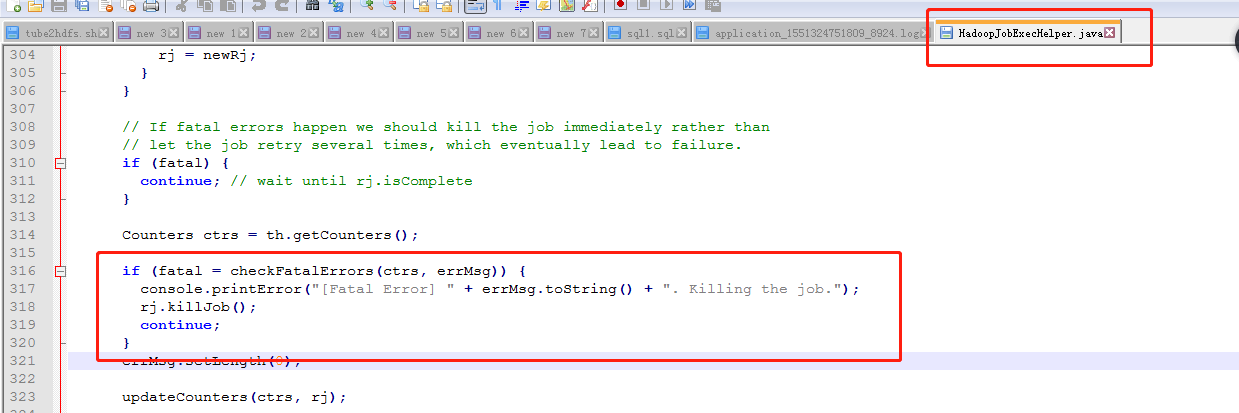
这段源码在Hive的源码处:\apache-hive-2.2.0-src\ql\src\java\org\apache\hadoop\hive\ql\exec\mr\HadoopJobExecHelper.java,第316到320行:
1 | if (fatal = checkFatalErrors(ctrs, errMsg)) { |
因此,我们对比日志信息和hive源码信息,可以基本确定,上述日志才是程序真正下发kill命令的根源。
3.2 错误的根源所在
那么怎么解释上述错误的原因呢?这个错误的原因是因为Hive对创建文件的总数有限制(hive.exec.max.created.files),默认是100000个。而客户运行的SQL任务,“万亿级大表 join 普通表” 的关联多维分析任务,在yarn上面观察启动了114486个mapper任务、0个reducer任务:
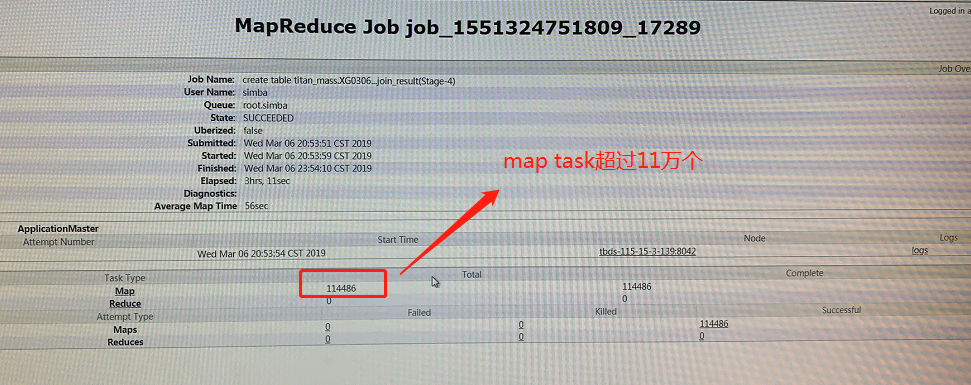
因为每个mapper任务会在HDFS上面创建一个临时文件,因此整个任务需要创建的临时文件也是11万多个,超过了hive.exec.max.created.files默认设置的100000个,因此才会触发hive源码里面的kill命令。为了能够成功地运行上述的SQL,最简单的方法就是加大hive.exec.max.created.files参数的设置。
同时,考虑到分区表的限制因此,我们通过设置以下参数:
1 | hive.exec.dynamic.partition=true; |
将hive.exec.max.created.files提高到500万,动态分区参数提高到500万(单节点50万),再次运行任务。最终发现,客户提交的就是“万亿级大表 join 普通表”的海量数据关联多维分析任务运行成功:
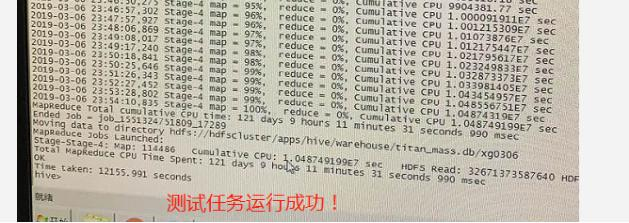
四、总结
本次客户反馈的 “万亿级大表 join 普通表” 的海量数据关联多维分析任务运行失败故障,也给腾讯云大数据技术支持工作足足上了一堂课:对于真正的海量数据分析场景,系统优化需要做到极致。就拿本次 “万亿级大表 join 普通表” 的hive sql任务而言,如此海量数据分析的任务,使用Hive集群默认参数肯定是要吃亏的。Hadoop的基础组件HDFS、Yarn、mapreduce、Hive、HBase等,在海量数据场景下各种参数都是需要优化到极致的。因此,本次故障排查与优化过程,确确实实让我们意识到,在以后的腾讯云toB大数据项目技术支持过程中,提前对超过100台服务器、数据量超过百TB(甚至PB级)的大型集群进行各种性能优化。
当然,除了大数据集群自身优化以外,数据本身优化也挺重要。比如对于HDFS而言,严格控制小文件数量;对于Hive而言,做好分区以及数据切斜控制;对于HBase而言,设计好regionserver的GC机制等。这些都是需要在部署完成大数据集群以后,提前进行优化。
 微信
微信 支付宝
支付宝











{kind=link}