

深入源码分析下 HIVE JDBC 的超时机制及其如何配置 socketTimeOut
1. 从一个常见的 HIVE JDBC SocketTimeoutException 问题聊起
在并发较高负载较大的大数据集群中,执行 HIVE SQL 常见的一个问题是 SocketTimeoutException 超时,即 “org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out”,其完整报错信息如下;
针对 HIVE JDBC 这类 SocketTimeoutException 超时问题,除了想办法提高集群性能或降低集群负载(比如错峰执行),我们也可以在HIVE JDBC 客户端,在应用级别配置使用更大的 hive thrift socket time out,从而减小 SocketTimeoutException 发生的概率;
由于 hive 的 SocketTimeout,其底层直接获取的是 HiveConnection 的 LoginTimeout,而 HiveConnection 的 LoginTimeout,目前所有版本的HIV ...

CentOS 7(Linux系统) 安装sqlserver
练习环境:centos7,内存2G以上
安装步骤1.1:设置sqlserver安装镜像:(不同的linux版本要找对应的sqlserver数据库版本,不然会有问题)
1curl https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repo > /etc/yum.repos.d/mssql-server.repo
1.2:镜像下载完成后,执行安装
1yum install -y mssql-server
1.2.1:如果你环境比较干净,可能还要手动安装一下yum(看自己版本,-7 -8要对应,不然用不了)
1wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
1.3:安装完后,会提示让你执行代码,配置一下数据库
1sudo /opt/mssql/bin/mssql-conf setup
1.4:配置完后会自动运行数据库服务,也可以手动查看
1.4.1:如果安装失败的话,提示你…Error: ...

SQL Server 基础命令及报错汇总
数据库基本使用命令1234567891011121314151617181920212223242526272829303132333435363738394041-- 创建数据库,指定编码格式CREATE DATABASE suggest_cm COLLATE Chinese_PRC_CI_AS;use suggest_cm;-- 创建数据库登录用户CREATE LOGIN suggest_cm WITH PASSWORD = 'Suggest@cm';CREATE USER suggest_cm FOR LOGIN suggest_cm;-- 数据库所有权,【切换到对应数据库执行】,否则当前用户无法访问数据库ALTER ROLE db_owner ADD MEMBER suggest_cm;------------------------------------------------------------### 修改字符集报错--1. 先改为单用户模式ALTER DATABASE suggest_cm SET SINGLE_USER WITH ROLLBAC ...

理解``(ds|hr)?+.+``
在hive/spark sql可以支持对列名进行正则匹配,其中给出这样一个 例子:
A SELECT statement can take regex-based column specification in Hive releases prior to 0.13.0, or in 0.13.0 and later releases if the configuration property hive.support.quoted.identifiers is set to none.
1SELECT ``(ds|hr)?+.+`` FROM sales
这个查询会查找除了ds和hr之外的所有列。这个正则实在是太过少见,查阅了很多资料才理解了。
首先要正确拆分(ds|hr)?+.+,(ds|hr)?+是一段,后面.+是第二段。这里面难点在于(ds|hr)?+的意义,子匹配(也就是括号)后面跟了两个量词?+,这是特殊用法,按照一般的量词意义是无法理解的,这个用法就是占有优先量词。正则的量词包括忽略优先、匹配优先、占有优先,占有优先是最大匹配后不“交还”,这点和匹配优先相反。这个例 ...

Hive中collect_list()排序问题详解
来看一道互联网公司的面试题:
123有个用户好友表:字段如下uid fans_uid score返回:uid, fans_uid_list【fans_uid的拼接串,按照score降序拼接】
给出数据源:每个uid,有很多对应的fans_uid,每个fans_uid 都对应一个score,我们需要按uid分组,将fans_uid 的score按降序排序,将fans_uid 放在一个列表中,做好友推荐
123456789101112131415161718192021222324252627create temporary table tb_user_fans as select 1 as uid,'a' as fans_uid,3 as scoreunion allselect 1 as uid,'b' as fans_uid,1 as scoreunion allselect 1 as uid,'c' as fans_uid,4 as scoreunion allselect 1 as uid,'d& ...

解决项目版本冲突——maven-shade插件使用
背景当我们在maven项目中引入第三方组件时,三方组件中的依赖可能会与项目已有组件发生冲突。
比如三方组件中依赖httpclient的版本是4.5.x,而项目中已有的httpclient版本是3.1.x,那么此时就会产生一下两种情况:
如果用三方组件的高版本httpclient覆盖原有的低版本httpclient,有可能会导致原来项目启动运行失败。即使高版本兼容低版本,也不能允许开发人员有这样高风险的操作
如果在三方maven依赖中对其对依赖的httpclient在引入时使用进行排除,使三方组件使用项目中的低版本httpclient,此时可能会因为版本不一致导致三方组件无法使用
在这样的情况下我们应当如何保证不影响项目原有依赖版本的情况下正常使用三方组件呢?此时可以考虑使用maven-shade-plugin插件
maven-shade-plugin介绍maven-shade-plugin 在maven官方网站中提供的一个插件,官方文档中定义其功能如下:
This plugin provides the capability to package the artifact i ...

四月之声,上海疫情爆发一个月
以下内容来源于网络:原文链接 默认静音播放,可手动调节打开音量
上海疫情爆发一个月,网上看到过的太多发声,没过多久就消失了一大半,时间长了已经有些麻木,但有些事情不应该发生,既然发生了也不应该被遗忘。太多同胞受了本可以避免的苦,全国这么多支援的情况下怎么还会变成这样呢?
2022年四月的上海能在家不挨饿的已经属于幸运。作为电影人,在亲身经历后如果什么也不做真的有些负罪感。因为时长原因最后选取了四月上旬二十多个事件的部分音频,正好也有无人机能纪录下周边现在的样子,做了一个视频当做一种尽量客观真实的纪录,来记住4月的这些声音,希望所有人都能挺过去。
愿山河无恙,愿人间皆安!
让我们一起守沪!上海!加油!

Hive 优化之SQL优化
小表 Join 大表 将 key 相对分散,并且数据量小的表放在 join 的左边,可以使用 map join 让小的维度表先进内存。在 map 端完成 join。 实际测试发现:新版的 hive 已经对 “小表 JOIN 大表” 和 “大表 JOIN 小表” 进行了优化。小表放在左边和右边已经没有区别。
MapJoin 工作机制
参数设置1234-- 设置自动选择 Mapjoinset hive.auto.convert.join=true; -- 默认为 true-- 大表小表的阈值设置(默认 25M 以下认为是小表)set hive.mapjoin.smalltable.filesize=25000000;
样例 SQL 1. 小表 JOIN 大表语句
1234select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_urlfrom smalltable sjoin bigtable bon b.id = s.id;
2. 大表 JOIN 小表语句
1234select b.id, b.t, b ...
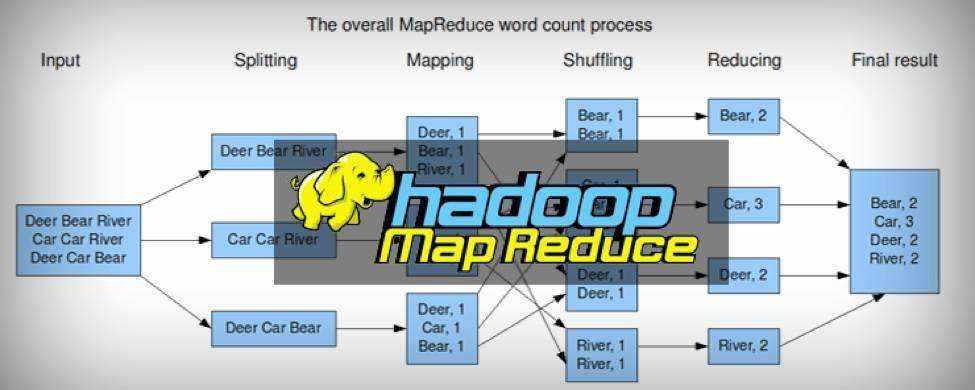
Hive 优化总结整理版
慎用api 我们知道大数据场景下不害怕数据量大,害怕的是数据倾斜,怎样避免数据倾斜,找到可能产生数据倾斜的函数尤为关键,数据量较大的情况下,慎用 count(distinct),count(distinct) 容易产生倾斜问题。
设置合理的map reduce的task数量map阶段优化1234mapred.min.split.size: -- 指的是数据的最小分割单元大小;min的默认值是1Bmapred.max.split.size: -- 指的是数据的最大分割单元大小;max的默认值是256MB通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
举例: a. 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128M的块和1个12M的块),从而产生7个map书; b. 假设input目录下有3个文件a,b,c,大小分别为10M,20M,130M,那么hadoop会分隔成4个块(10M,20M,128M,2M ...

使用Hive SQL插入动态分区的Parquet表OOM异常分析
一、异常描述
当运行“INSERT … SELECT”语句向Parquet或者ORC格式的表中插入数据时,如果启用了动态分区,你可能会碰到以下错误,而导致作业无法正常执行。
Hive客户端:
12345678Task with the most failures(4):Diagnostic Messages for this Task:Error: GC overhead limit exceeded...FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTaskMapReduce Jobs Launched:Stage-Stage-1: Map: 1 HDFS Read: 0 HDFS Write: 0 FAILTotal MapReduce CPU Time Spent: 0 msec
YARN的8088中查看具体map task报错:
12017-10-27 17:08:04,317 FATAL [main] org.apache.hadoop.mapred.Ya ...






{kind=link}