

运行Mapreduce作业出现Java heap space解决方案
在一次吃饭间隙听到身边的朋友说到:“为什么我的mapreduce作业总是运行到某个阶段就报出如下错误,然后失败呢?以前同一个作业没出现过的呀?”
1234519/01/10 12:48:01 INFO mapred.JobClient: Task Id : attempt_201001061331_0002_m_000027_0, Status : FAILEDjava.lang.OutOfMemoryError: Java heap space at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.<init>(MapTask.java:498) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:305) at org.apache.hadoop.mapred.Child.main(Child.java:158)
报错日志已经给出了,就是 Out Of Memory OOM的问题。
其实这样的错误有时候并不是程序逻辑的问题(当 ...

记一次MR报错:Container is running beyond physical memory limits...
背景较早之前项目组一次新需求上线时,需要初始化Hive中某张表的全量历史数据。该表由于历史原因导致ETL处理的时候,2015年前的数据产出文件(定长压缩文件)时为同一个ETL日期,也就是这张表的分区日期,由于涵盖多年的数据,并且数据文件较大又分为多个日期,数据存放Hive时需要按照其真实业务日期进行重分区。线上集群同时有部分Spark任务存在,所以决定采用Mapreduce方式进行解析入库并重分区到正式表(其中集群为CDH5.14.0)。
错误日志我们日常开发测试与生产环境物理隔离,日志无法获取,以下日志来源于CSDN)
123456789101112131415161718192021222324252627282930313233......18/05/15 09:36:59 INFO mapreduce.Job: Running job: job_1525923400969_002318/05/15 09:37:11 INFO mapreduce.Job: Job job_1525923400969_0023 running in uber mode : false18/05/1 ...
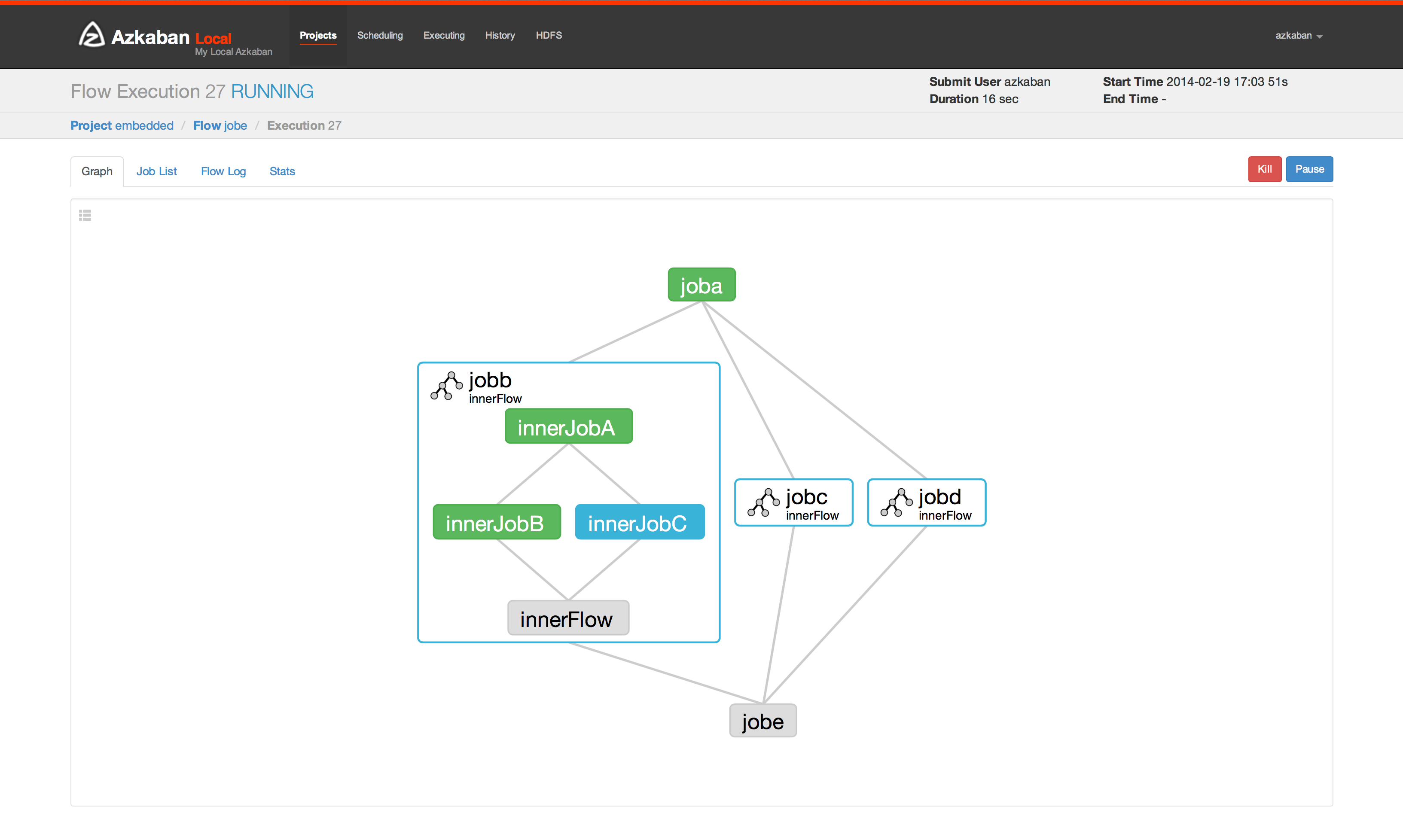
Azkaban任务调度工具简述
Azkaban任务调度Azkaban简述
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
Azkaban 是在LinkedIn上创建的批处理工作流作业调度程序,用于运行Hadoop作业。Azkaban通过作业依赖性解决订单,并提供易于使用的Web用户界面来维护和跟踪您的工作流程。
特征:
兼容任何版本的Hadoop
易于使用的Web UI
简单的Web和http工作流上传
项目工作区
调度工作流程
模块化和可插入
身份验证和授权
跟踪用户操作
有关失败和成功的电子邮件提醒
SLA警报和自动查杀
重试失败的工作
以上来自官方介绍,详情见 官网
为什么需要工 ...

Markdown基本语法教程
Markdown 应用
Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。
Markdown 语言在 2004 由约翰·格鲁伯(英语:John Gruber)创建。
Markdown 编写的文档可以导出 HTML、Word、图像、PDF、Epub 等多种格式的文档。
Markdown 编写的文档后缀为 .md 或 .markdown。
Markdown 能被使用来撰写电子书,如:Gitbook。
当前许多网站都广泛使用 Markdown 来撰写帮助文档或是用于论坛上发表消息。例如:GitHub、简书、reddit、Diaspora、Stack Exchange、OpenStreetMap 、SourceForge 等。
Markdown 标题Markdown 标题有两种格式。
使用 = 和 - 标记一级和二级标题= 和 - 标记语法格式如下:
12345一级标题=======二级标题-------
使用 # 号标记使用 # 号可表示 1-6 级标题,一级标题对应一个 # 号,二级标题对应两个 # 号,以此类推。
123456# 一级标题## ...

SSL证书 基于Nginx配置Https
前言 最近一段时间在搞自己的博客网站,本地环境一直使用的HTTP协议,但在上线发布到个人服务器后还使用HTTP访问就有点说不过去了。
另外博客网站的基础架构为 Hexo框架 + Butterfly主题 + 博客后端管理(自己开发便于管理博客);此处涉及到自己个人后台服务以及服务端数据库的基本操作,还包括阿里云OSS存储对象。考虑至此,还是打算安装SSL证书,采用HTTPS方式堆外提供访问(其实最多的想法还是担心对于不搞程序的盆友们一看到不安全的链接就直接劝退了,这是万万伤不起的)。毕竟自己也是土生土长的程序猿,怎么能容忍此种情况发生。
虽然自己之前没搞过Nginx方面的东西,但这些都不是问题,只有一句话:“没有不会搞,只有不想搞”。
使用的环境如下:
123服务器: 腾讯云轻量应用服务器(1G,2core)centos: 7.6nginx: 1.8.0
申请证书 此处采用的是腾讯云域名解析,首选先申请个人域名,并添加至域名解析中。
点击域名进入域名记录列表配置页,添加域名解析记录:
添加完成后可在页面最上端前往 DNSPod控制台 进行SSL证书申请,找到刚刚添加的记录值,如图操作 ...

CDH集群磁盘故障换盘处理
前言前段时间公司线上CDH集群突然异常报警,经过查验后发现是其中一个数据节点所在的服务器上某块磁盘无法读写,导致当前DataNode节点读写异常。随后登录到故障节点进行手动验证,进入到损坏磁盘的挂载目录,预创建文件进行读写操作,发现直接报错,查看报错信息,确实是当前磁盘无法读写异常。
问题已经足以说明是磁盘损坏了,那接下来就是换盘操作了,由于机房不在本地(公司),所以同时联系运维同时进驻机房,进行手动换盘,然后在服务器上再进行设置。
由于我本人不是做运维方面的,关于服务器一些常用的命令使用起来基本没什么问题,但是像磁盘挂载这方面的操作还是比较生疏的,虽然之前有了解过一些,也在自己本机进行过配置,但毕竟不是生产环境,差别还是有的。并且公司有专门的运维同事负责我们项目组线上的集群(但是只负责服务器相关的运维操作,CDH集群包括项目组线上所有运行的服务还得我们自己排查自己搞,有时候都怀疑自己除了是大数据开发,还附带兼职运维图片)。
玩笑归玩笑,工作上的事情该做还是要好好做,不能给后人“唾骂”的机会。那么本文主要讲述磁盘故障需要在线换盘时,CDH集群需要做的操作有哪些。
为DataNode执行 ...

Git同时连接Github和Gitee
前言一开始,自己想的多了,看了很多文章,而每篇文章都存在些许差异,自己就犯难了。后来突然想明白了,其实Gitee和Github验证的方式完全一样,不就是使用不对称加密来完成验证的吗。想明白了这一点,剩下的流程了就简单了。只需要生成两对公钥和私钥即可。具体操作流程如下。
生成两对公钥和私钥PS:我是在全新的系统上配置的,即不存在原来相关账户和配置的残留,如果有残留,据说要先解绑(删除配置),具体操作如下:
12git config --global --unset user.name "yourname"git config --global --unset user.email "yourEmail@163.com"
下面是真正的生成公钥和私钥:
12ssh-keygen -t rsa -C 'yourEmail@163.com' -f ~/.ssh/id_rsa_githubssh-keygen -t rsa -C 'yourEmail@163.com' -f ~/.ssh/id_rsa_gitee
生成 ...

Centos6安装nodejs报libstdc版本低问题解决
查看node版本
1node -v
node版本的管理模板
1npm i -g n --force
升级node
12345678#稳定版n stable#最新版n latest#指定版本n 版本号 #如 n 10.0.0
常见问题
1234567node: /usr/lib64/libstdc++.so.6: version ``GLIBCXX_3.4.14' not found (required by node)node: /usr/lib64/libstdc++.so.6: version ``GLIBCXX_3.4.18' not found (required by node)node: /usr/lib64/libstdc++.so.6: version ``CXXABI_1.3.5' not found (required by node)node: /usr/lib64/libstdc++.so.6: version ``GLIBCXX_3.4.15' not found (required by node)node: /lib ...

Hexo博客搭建四(添加Valine评论)
前言本博客采用了 Twikoo 和 Valine 双评论系统,其中 Twikoo 是基于腾讯云开发CloudBase开发,Valine 是基于LeanCloud应用进行搭建,两者都支持微信、QQ评论提醒,Twikoo还支持QQ邮箱提醒。
本文主要讲述基于LeanCloud应用的Valine评论系统的搭建与使用,Twikoo将在下篇文章进行叙述。
由于在搭建本博客时部分步骤及设置没有及时进行笔记记录,只记录了一些核心重要的步骤,所以本教程主要参考了大佬们的杰作,各位童鞋在进行搭建时可供参考,如有问题可至文章末尾评论留言,小菜鸟看到后会进行一一解答。(说是有点小瑕疵,但其实都不时是什么问题,相信大家还是可以自己解决的)
创建LeanCloud应用注册我就不多说了,有手有脑都会
注意:一定要选择国际版,如果你选择的是华北或者华东的话,Valine 后台评论管理是需要备案才能绑定的.
打开LeanCloud官网:https://console.leancloud.app/#/app注册登陆后长这样由于小菜鸟已经创建过了应用,所以登录后的页面中会有记录,同学们刚注册登录后是没有的,需要新建应用。 ...

Hexo博客搭建三(网站多媒体)
网站设置Aplayer音乐播放器如果需要使用更多的功能及参数配置,可安装hexo-tag-aplayer插件。此处采用安装插件的方式进行设置。
12# 安装插件:npm install --save hexo-tag-aplayer
1. 关闭 asset_inject由于需要全局都插入aplayer和meting资源,为了防止插入重复的资源,需要把asset_inject设为false,在Hexo的配置文件中
123aplayer: meting: true asset_inject: false
2. 开启主题的aplayerInject在主题的配置文件中,enable 设为 true 和 per_page 设为 true
1234# Inject the css and script (aplayer/meting)aplayerInject: enable: true per_page: true
3. 插入Aplayer html把aplayer代码插入到主题配置文件的inject.bottom去
1234inject: head: bottom: - &l ...






{kind=link}